L'intégration de l'IA générative dans les processus de développement transforme radicalement l'expérience développeur, ainsi que les *soft* et *hard* skills attendues.
Avec sa mise à jour 2025, la FinOps Foundation fait tomber les cloisons : désormais, toutes (ou presque) les ressources IT — SaaS, datacenters, IA, cloud public — entrent dans le radar
Agacé par un résultat non pertinent de votre IA générative préférée, vous avez déjà tenté de changer des éléments de votre prompt ? Si oui, alors comme M. Jourdain qui pratiquait la prose naturellement, vous avez eu recours au prompt engineering.
Le résultat fut-il meilleur ? Probablement, mais certainement toujours loin de vos attentes initiales. Vous avez ainsi touché du doigt les limites de "l'ingénierie de la requête". Le prompt engineering est une vraie compétence, utile, mais il serait illusoire de penser 1) les utilisateurs maîtriseront cet art, et 2) que cela résoudra les soucis de pertinence du contenu.
Le vrai sujet : offrir un dialogue avec le SI en langage naturel
Ce qui donnera véritablement de la valeur à vos applications d'IA générative en entreprise, c'est la capacité offerte aux collaborateurs d'accéder au patrimoine informationnel à travers un dialogue en langage naturel. D'obtenir des réponses pertinentes pour leur domaine d'activité, pour leur métier. Le niveau d'optimisation de la requête sera un plus, qui pourra s'affiner au fil du temps.
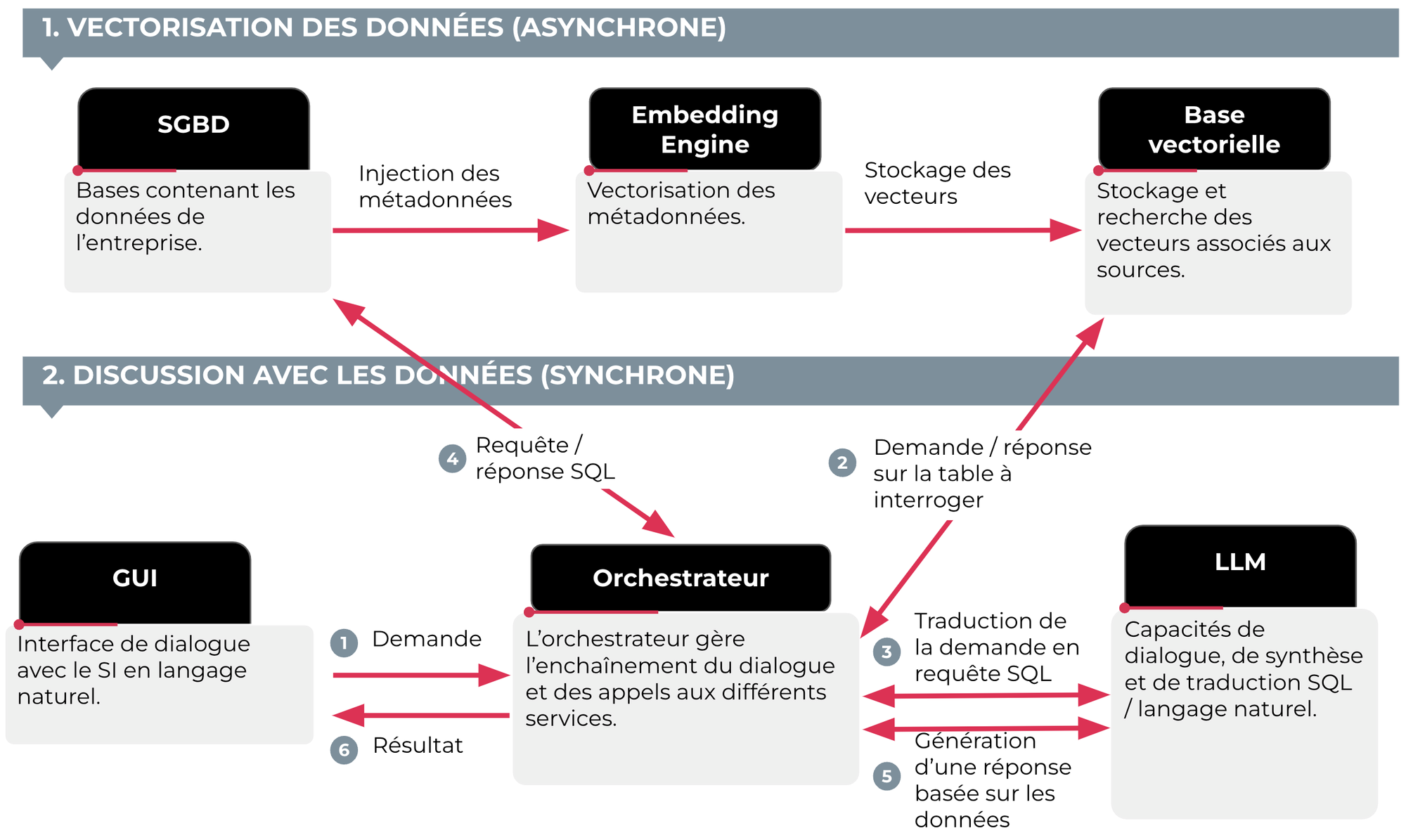
Cela nécessite de mettre en place du RAG (Retrieval Augmented Generation) : une architecture qui va combiner la puissance des LLM pour la compréhension des questions et la formulation des réponses et le contenu des documents des utilisateurs (RAG sur des PDF individuels) voire des bases d’informations des entreprises.
Donner ainsi accès aux données et documents demande de les vectoriser au préalable. Typiquement, vous disposez de dizaines de documents techniques, des PDF de plusieurs dizaines de pages, et vous souhaitez permettre à vos collaborateurs d'interroger cette base de connaissance en langage naturel comme s'ils discutaient avec un documentaliste. Il faut alors passer par une phase dite d'embedding : la création de vecteurs représentant leur contenu, que les moteurs d'IA générative sont capables d'interpréter.
Processus en 2 temps afin de pouvoir dialoguer avec les données de l'entreprise
Embedding de documents et données structurées
Cette vectorisation du contenu de l'entreprise est aussi réalisable pour les données structurées : chiffres de vente, nombre d'employés, indicateurs RSE, etc. C'est là où la promesse de l'IA générative en entreprise devient exceptionnelle. C'est là également que le prompt engineering prend tout son sens : selon l'habileté qu'on aura à formuler des prompts pour dialoguer avec le SI, les résultats pourront être très différents.
D'où l'importance de coupler ces nouvelles interfaces de chat avec des bibliothèques de prompt : des questions peaufinées, dont on sait qu'elles généreront des résultats pertinents.
Bien entendu, cela demande de prendre quelques précautions. Les bases de données doivent être correctement renseignées et les métadonnées intelligibles. Il faut trouver le bon découpage des documents (en “chunks” analysables par les LLM). Il faut aussi se prémunir contre des risques de sécurité (SQL injection). Mais très clairement, cette approche de requêtage en langage naturel est idéale pour de très nombreux utilisateurs qui pourront s’appuyer sur un assistant personnel pour naviguer au sein du patrimoine informationnel de l’entreprise.