
Approches IA générative : Prompt, RAG, Fine-tuning, Training
Il n'est pas évident de s'y retrouver dans toutes ces approches de mise en oeuvre de l'IA générative, voici un guide pour comprendre et choisir l'approche qui sera la plus adaptée à votre contexte.
En plus de présenter chaque approche, je vous propose de les comparer sur les axes d'analyses suivants :
🔵 Exactitude (dans quelle mesure les réponses peuvent-elles être exactes ?)
Complexité de la mise en œuvre (dans quelle mesure la mise en œuvre peut-elle être complexe ?)
🔵 Effort (Quel effort faut-il pour mettre en œuvre ?)
🔵 Coût total de possession (TCO) (Quel est le coût total de possession de la solution ?)
🔵 Facilité des mises à jour et des modifications (dans quelle mesure l'architecture est-elle faiblement couplée ? Dans quelle mesure est-il facile de remplacer/mettre à niveau les composants ?)
Présentation des approches
🔍Prompting : Parfaite pour les cas d'utilisation ne nécessitant pas un contexte de domaine profond, cette méthode offre une grande flexibilité sans nécessiter de compétences en programmation avancées.
🔍Génération Augmentée par la Recherche (RAG) : Idéale si vous cherchez à maintenir une haute qualité de réponse tout en ayant la possibilité de modifier différents composants (sources de données, embeddings, modèles de langage, moteurs vectoriels).
🔍Affinage (Fine-tuning) : Choisissez cette approche pour un contrôle accru sur l'artefact du modèle et la gestion de sa version, particulièrement quand les terminologies spécifiques au domaine sont cruciales.
🔍Entrainement de modèle (Training) : La route à prendre si aucune des options ci-dessus ne répond à vos besoins et que vous disposez de données bien organisées, d'une infrastructure sophistiquée et de budgets conséquents.
Comparatif de chaque approche
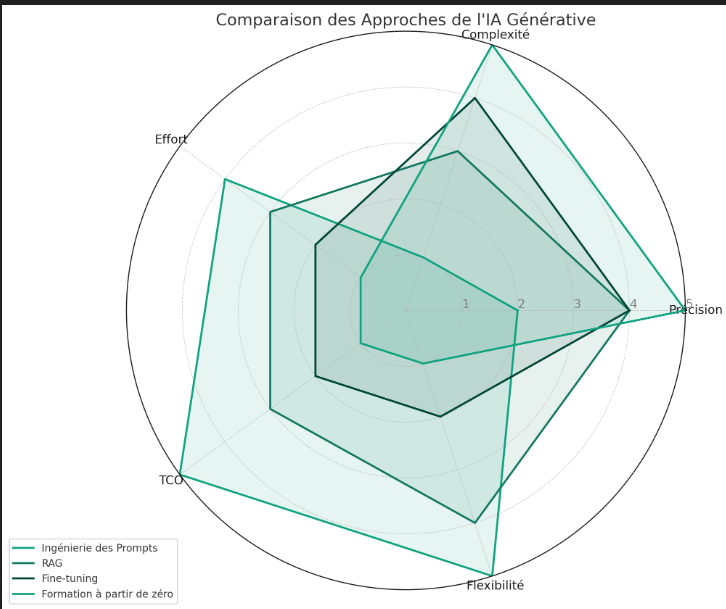
1. Ingénierie des Prompts :
- Précision : Produit les résultats les moins précis par rapport aux autres méthodes, bien que les résultats puissent sembler impressionnants isolément.
- Complexité de mise en œuvre : Relativement faible, nécessite peu ou pas de compétences en programmation.
- Effort : Nécessite beaucoup d'efforts itératifs pour affiner les prompts et obtenir la réponse correcte.
- Coût total de possession (TCO) : Assez faible, principalement lié à la maintenance des modèles de prompt.
- Flexibilité aux changements : Très élevée, les modèles de prompts peuvent être facilement modifiés pour s'adapter à de nouvelles versions de FM ou à de nouveaux FM.
2. Génération Augmentée par la Recherche (RAG) :
- Précision : Fournit des résultats de haute qualité, avec une précision améliorée par rapport à l'ingénierie des prompts grâce à l'utilisation de contextes spécifiques.
- Complexité de mise en œuvre : Plus élevée que l'ingénierie des prompts en raison des compétences en codage et en architecture nécessaires.
- Effort : Exige un niveau d'effort modéré, supérieur à celui de l'ingénierie des prompts.
- Coût total de possession (TCO) : Plus élevé que pour l'ingénierie des prompts, en raison des multiples composants impliqués.
- Flexibilité aux changements : La plus élevée, permettant des modifications indépendantes des différents composants.
3. Fine-tuning :
- Précision : Produit des résultats très précis, potentiellement de qualité légèrement supérieure à celle de RAG, en fonction du cas d'usage.
- Complexité de mise en œuvre : Plus élevée que pour l'ingénierie des prompts et RAG, nécessitant une expertise en science des données et en ML.
- Effort : Plus important que pour les deux autres méthodes, même si le fine-tuning peut nécessiter relativement peu de données.
- Coût total de possession (TCO) : Plus élevé que pour RAG et l'ingénierie des prompts en raison de la puissance de calcul requise et de la compétence technique nécessaire.
- Flexibilité aux changements : Faible, car des changements dans les données ou les entrées nécessitent un nouveau cycle de fine-tuning.
4. Training :
- Précision : Produit les résultats de la plus haute qualité, avec les chances les plus faibles d'erreurs par rapport aux autres approches
- Complexité de mise en œuvre : La plus élevée, nécessitant une grande quantité de données, de l'expertise en science des données et en ML
- Effort : Le plus élevé, impliquant un développement itératif considérable pour obtenir un modèle optimal.
- Coût total de possession (TCO) : Le plus élevé, en raison des besoins élevés en matière de traitement de données et d'entraînement du modèle.
- Flexibilité aux changements : La plus faible, car les mises à jour du modèle nécessitent de nouveaux cycles d'entraînement.
Continuer votre exploration
Découvrez d'autres articles du cluster ia-generative dans l'univers Intelligence Artificielle