L'intégration de l'IA générative dans les processus de développement transforme radicalement l'expérience développeur, ainsi que les *soft* et *hard* skills attendues.
Avec sa mise à jour 2025, la FinOps Foundation fait tomber les cloisons : désormais, toutes (ou presque) les ressources IT — SaaS, datacenters, IA, cloud public — entrent dans le radar
Bénéficier de la puissance des LLM en entreprise : du PoC à l'industrialisation
Vous vous demandez comment tirer les bénéfices des LLM tout en garantissant sécurité, robustesse et conformité ? Découvrez notre démarche de construction d'une stack LLM d'entreprise en 4 étapes, du PoC à l'industrialisation.
Le gain de productivité que ChatGPT génère ne doit pas occulter les risques élevés liés à son usage, en particulier le danger de fuite de données, Samsung en a fait les frais dès mars 2023, mais aussi en matière de qualité des informations retournées aux employés. Autrement dit, pour un CIO : comment fournir à mes employés un outil de gain de productivité comme ChatGPT, sans exposer mon entreprise à des fuites massives de données confidentielles et en limitant les hallucinations ?
Interdire ChatGPT est nécessaire, mais n'est pas suffisant. Les CIO doivent fournir à leurs salariés une instance robuste, sécurisée et gouvernée. En complément de notre étude TechWaves Gen AI for CIOs & CTOs, voici une démarche itérative possible, s'appuyant sur 4 grandes étapes de construction d'un LLM stack d'entreprise.
Disclaimer : cet article se concentre sur les composants technologiques à mettre en oeuvre, mais une démarche globale inclut d'adapter son organisation et d'acculturer ses collaborateurs à cette nouvelle technologie.
Etape 1 : démarrer avec un PoC
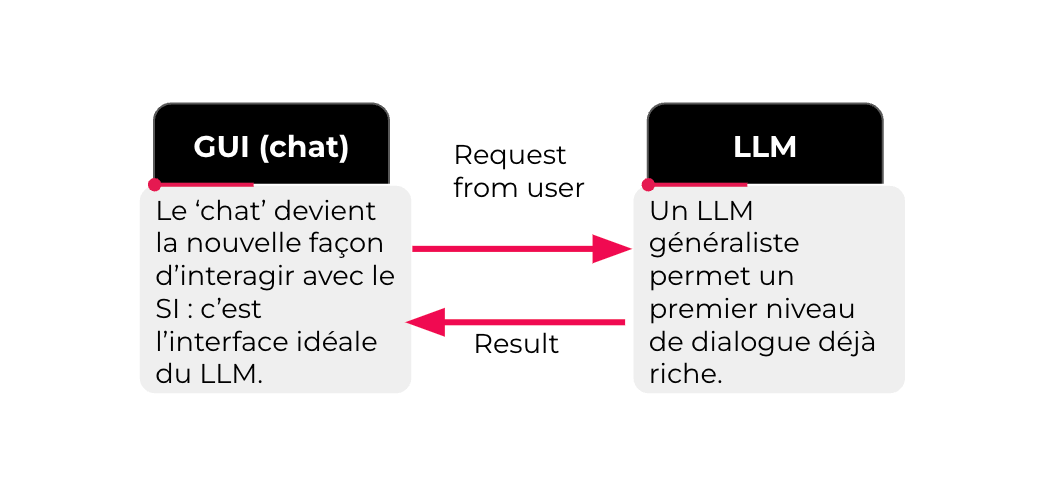
Le premier enjeu pour une entreprise est de pouvoir mettre à disposition de ses salariés une version sécurisée d'un agent conversationnel type ChatGPT. Pour ce faire, elle doit déployer une instance de LLM généraliste dans son environnement et le connecter à une interface de type chat. Cette première étape permet de valider de premières hypothèses telles que le modèle de langage le plus approprié, ou encore l'ajustement de certains paramètres qui jouent sur la créativité du modèle (la température par exemple).
Cette première étape est également un moyen pour les entreprises de collecter les cas d'usage des collaborateurs à travers les questions posées, et ainsi d'améliorer les prochaines versions de ce produit grâce à diverses techniques de fine tuning.
Le risque de fuite des données vers l'extérieur est levé, néanmoins le travail sur la pertinence des informations transmises par le LLM reste à approfondir dans les cycles de développement ultérieurs.
Etape 2 : un MVP pour se forger de premières convictions sur un LLM customisé avec les données de l'entreprise
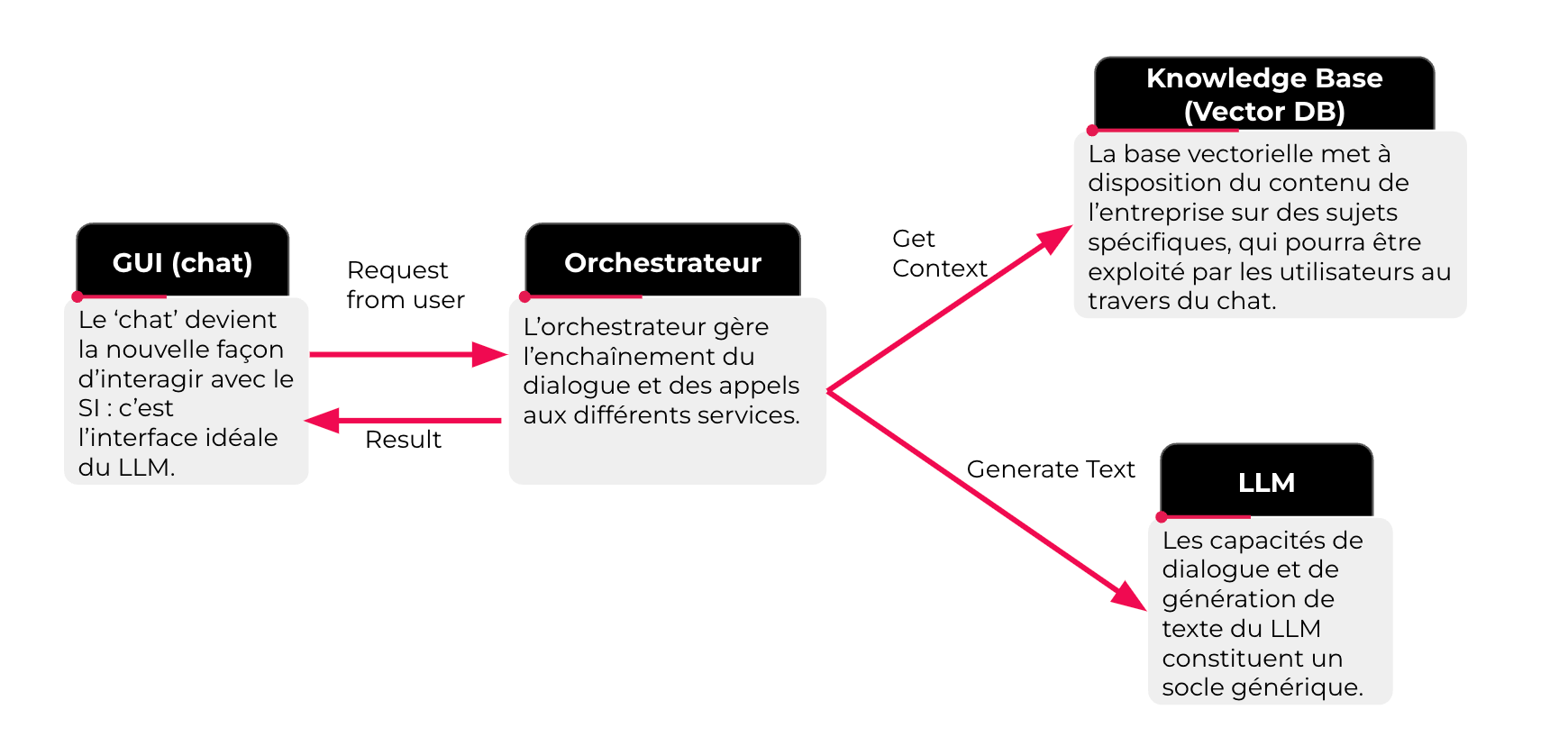
L'étape du MVP a pour objectif principal de personnaliser le contenu généré avec des données de l'entreprise. Pour ce faire, deux nouveaux composants entrent en jeu dans cette architecture : les bases de données vectorielles et un orchestrateur.
La base de connaissance, encapsulée dans les bases de données vectorielle, est externalisée du LLM qui n'a pour fonction que celle de la rédaction, synthèse d'un texte en langage naturel. L'orchestrateur assure l'enchaînement entre les différents services pour assurer la continuité du dialogue. L'orchestrateur peut également conserver les sources d'information et les restituer à l'interface, ce qui permet à l'utilisateur de retrouver le document sur lequel la réponse a été construite.
Cette étape permet d'expérimenter l'articulation entre un corpus de données sélectionné par l'entreprise et un LLM. La qualité des résultats reposera ici grandement sur les prompts formulés en entrée, dans l'interface, et donc sur les compétences de prompt engineering des utilisateurs.
Etape 3 : tirer les bénéfices du prompt engineering avec une basic LLM Stack
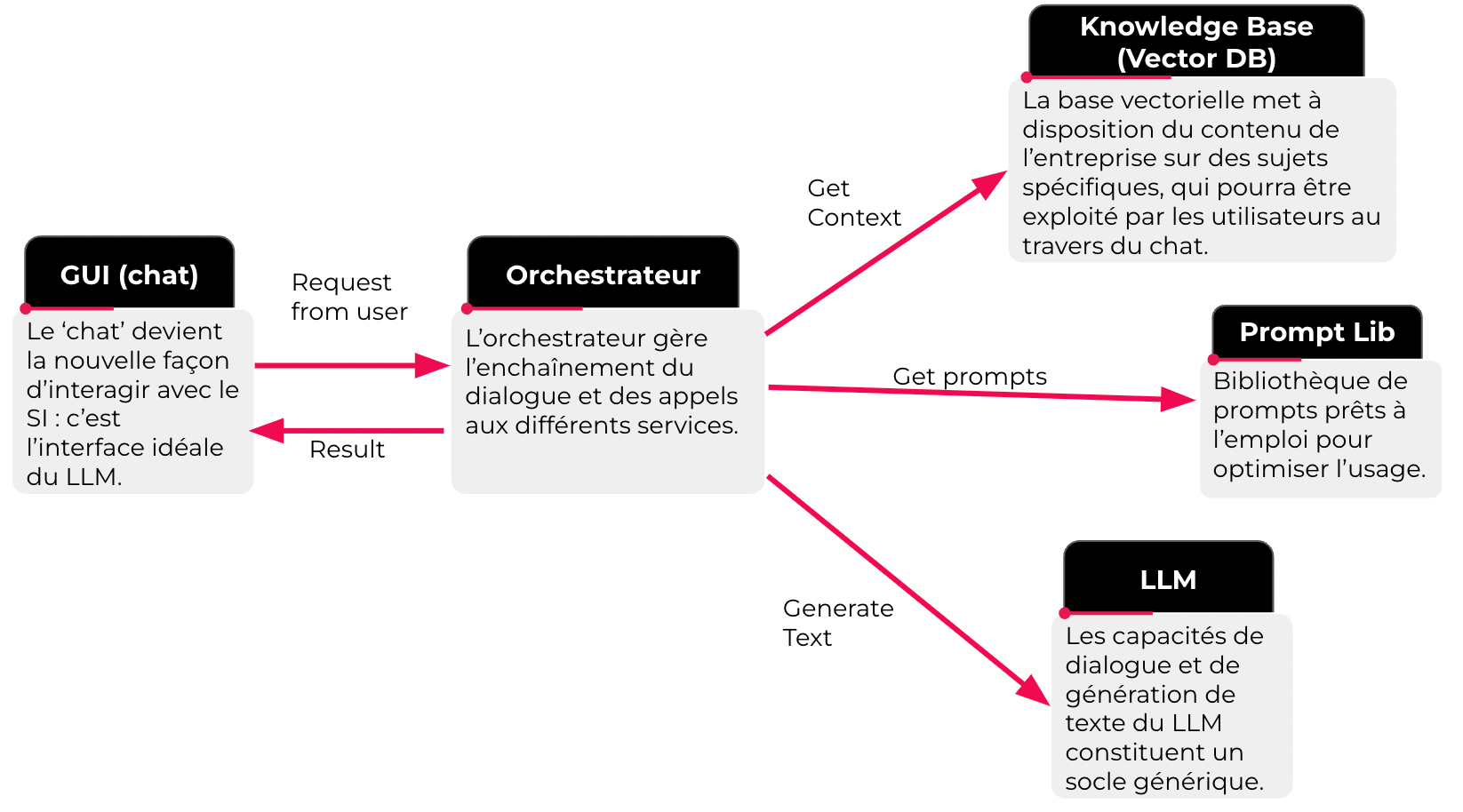
L'intelligence est dans le prompt. L'ajout majeur ici est donc le composant de bibliothèque de prompt ou "Prompt lib" qui répertorie des prompts prêts à l'emploi et optimisent ainsi l'usage du LLM. Le rôle de prompt engineer prend toute son ampleur lors de cette phase. Il aura pour mission de formuler des prompts de haute qualité pour obtenir les meilleurs résultats, en veillant à ce que l’IA génère des réponses précises, pertinentes et adaptées aux besoins spécifiques.
En intégrant ce composant après avoir pu analyser les premiers usages de l'application par les utilisateurs, les prompt engineers pourront se concentrer sur les cas d'utilisation à plus forte valeur ajoutée.
Etape 4 : industrialiser et pérenniser avec une advanced LLM stack
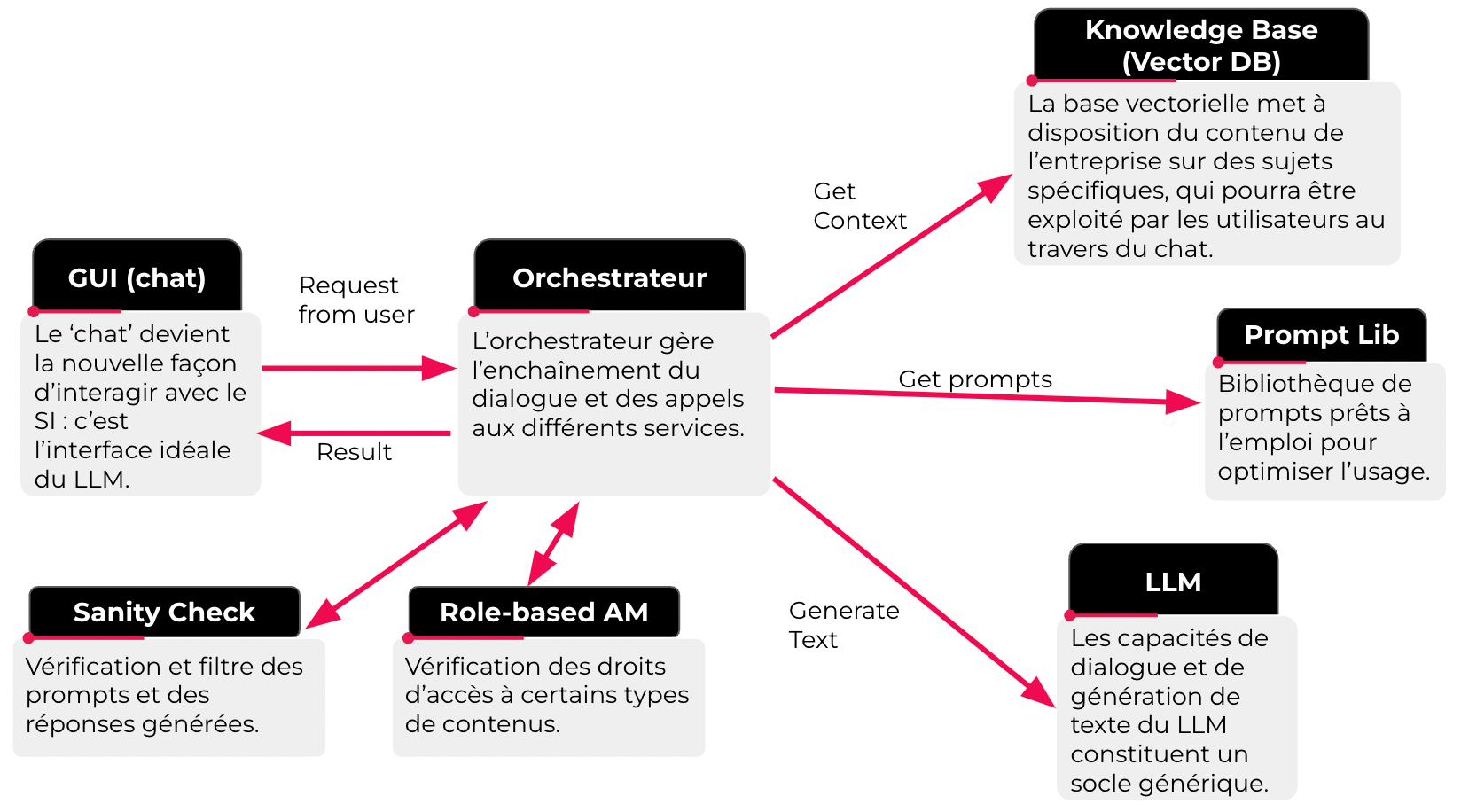
L'architecture d'une application basée sur des LLMs doit pouvoir répondre aux défis posés par son industrialisation et son utilisation à l'échelle, en particulier en terme de gouvernance et de conformité.
Le contrôle de la diffusion des données ne doit pas s'arrêter à l'externe, il est impératif d'appliquer les règles de gestion des accès à la donnée pratiquées par l'entreprise au sein de l'application LLM. C'est pourquoi l'orchestrateur doit pouvoir interroger l'access management tool des données dans l'entreprise.
L'éthique et la conformité sont aussi des enjeux majeurs en phase d'industrialisation d'une telle application. Un composant type "sanity check" permet de s'assurer du respect des normes éthiques de l'entreprise, en entrée et en sortie du modèle. Il permet également de suivre les performances de qualité du modèle sur le long terme.
Marie accompagne depuis 2017 les plus grandes entreprises françaises dans leurs transformations IA et Data en les aidant à construire leur vision et à les mettre en œuvre.
Avec sa mise à jour 2025, la FinOps Foundation fait tomber les cloisons : désormais, toutes (ou presque) les ressources IT — SaaS, datacenters, IA, cloud public — entrent dans le radar
Ce ne sera toujours pas pour 2025 : l'outil "miracle" pour la gouvernance des données n'existe pas ; il s'agit plutôt d'une démarche outillée, dont il est important de s'approprier les étapes.
Replay du webinaire du 6 février dernier, à l'occasion de la sortie de notre Livre blanc Tendances Tech 2025, réunissant des experts de SFEIR et WEnvision.